
今回は、Pythonのライブラリである「pandas」を用いたExcelの読み書きについて解説したいと思います。
他のライブラリを用いてもエクセルを操作することはできますが、「pandas」は使う機会が多いため、使えるようになると便利です。
1. 必要なライブラリのインストール
まず、「pandas」でexcelデータを読み書きするために必要なライブラリをインストールしましょう。
「pandas」でexcelを操作するためには、実は他にも必要なライブラリがあります。
読み込みと書き込みでぞれぞれ以下のライブラリが必要ですので、やりたい操作に応じてインストールしてください。
| ライブラリ | 使用内容 | 対象ファイル | 補足 |
| xlrd | 読み込み | .xls, .xlsx | 新旧どちらでも |
| xlwt | 書き込み | .xls | 古いexcel |
| openpyxl | 書き込み | .xlsx | 新しいexcel |
ここで少し補足をすると、excelは古いものと新しいもので拡張子がそれぞれ「.xls」と「.xlsx」に分けられています。
そして、書き込みを行う際はこの拡張子により必要なライブラリが異なるため、注意が必要です。
(excelのデータを扱う機会があるのであれば、全部入れておいても問題ないと思います。)
これでexcelデータを扱う準備ができたので、次の章からさっそくデータの読み書きについて解説していこうと思います。
- excelの読み書きには、「pandas」だけでは不十分
- 読み込みには「xlrd」が必要
- 書き込みには「xlwt」と「openpyxl」が必要
2. Excelデータの読み込み
では、まずexcelデータの読み込みについて解説します。
excelデータの読み込みには、「pandas.read_excel()」を使用します。
基本的にはcsvの読み込みと似た操作となります。
ただし、excelは、csvと違って1つのファイルで複数のsheetに分かれているため、その読み込みに多少の差があります。
では、実際にコードを動かしながら確認してみましょう。
下のようなエクセルを準備し、読み込んでみます。
Sheet1
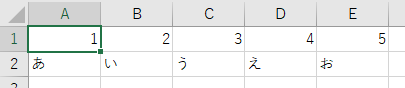
Sheet2
2.1 Sheetを指定した読み込み
まず、読み込むSheetの指定方法について解説します。
sheetの指定には、「sheet_name=」を使用します。
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name=0)
または、
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name='Sheet1')
これで、「Sheet1」を読み込むことができました。

上のコードのように、sheetの指定方法は、「前から何番目か」を数字で入力するか、「sheet名」を文字で入力するか、の2種類の方法があります。
これに関しては、どちらか扱いやすい方を利用されると良いと思います。
※ちなみに、前項でインストールしたライブラリですが、「pandas」でexcelを操作する際に内部で動いているだけなので、インポートする必要はありません。
2.2 複数のsheetの読み込み
次に、複数のsheetを一度に読み込む方法について解説します。
といっても、実は先ほどとあまり変わらず、「sheet_name」を「list」で受け渡すだけです。
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name=[0, 1])
すると、DataFrameが辞書型として読み込まれます。

そして、ここからデータを取り出したい時は「キー」を指定すれば取り出すことができます。
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name=[0, 1])
df1 = df[0]

Sheet1を単体で読み込んだ時と同じように読み込めていますね。
ちなみに、「sheet_name」に渡す「list」は「sheet名」でも構いません。ただしこの時は、「キー」も「sheet名」になります。
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name=["Sheet1", "Sheet2"])
df1 = df["Sheet1"]

2.3 すべてのsheetの読み込み
最後に、すべてのsheetを読み込む方法について解説します。
一つ一つ「list」で渡してもいいのですが、「sheet」が多い場合は少し大変ですよね。
そんな時は、「sheet_name=None」とすることで一括で読み込むことができます。
import pandas as pd
df = pd.read_excel("test.xlsx", sheet_name=None)

※ちなみにこの時の「キー」は「sheet名」になります。
これで、excelを「pandas」を使って読み込むことができました。
- excelデータの読み込みには、「pd.read_excel()」を使用
- sheetの指定には、「sheet_name=」を使用
- 複数sheetを読む場合は「sheet_name」を「lsit」で受け渡す
- すべてのsheetを読み込む場合は「sheet_name=None」
3. Excelへの書き込み
次に、pandasを利用したexcelへの書き込みについて解説します。
excelへの書き込みには、「df.to_excel()」を使用します。
※dfの部分はデータフレーム名
書き込みに使うためにインストールした「xlwt」と「openpyxl」も、pandasの内部で動くためインポートする必要はありません。
では、実際にコードを動かしながら確認してみましょう。
3.1 エクセルへの保存(新規作成 or 上書き)
まず、ファイルが無い場合は新規作成し、ファイルがある場合は上書き保存する方法について解説します。
基本的な使い方は、
「df.to_excel("ファイル名", sheet_name="シート名", index=True, header=True)」
という形です。
では、実際にexcelに出力してみます。下のコードを確認してください。
import pandas as pd
#書き出すデータの作成
data = [[80,75,90,70,95],[95,80,75,90,65]]
#行列名の作成
col = ["国語", "算数", "理科", "社会", "英語"]
ind = ["太郎", "花子"]
#dataframe作成
df = pd.DataFrame(data, columns=col, index=ind)
#書き出し
df.to_excel("out.xlsx", sheet_name="test", index=True, header=True)
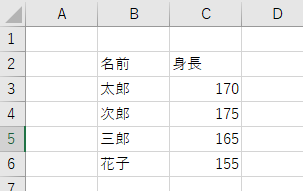
上のコードを実行すると、「out.xlsx」というexcelファイルに下のように出力することができます。

ここで、sheet名を指定しなかった場合は「sheet1」という名前になります。
ただ、「index」や「header」が要らないという場合もあると思います。そんな時は、要らない方を「False」にすれば出力を止めることができます。
df.to_excel("out.xlsx", sheet_name="test", index=False, header=False)

ちなみに、pandasのDataFrameの作り方は、下の講座で解説していますので
良ければそちらもご覧ください。

3.2 複数シートへの書き込み(複数データフレーム)
次に、データが複数ある場合の書き込みについて解説します。
データが複数ある場合は、「pandas.ExcelWriter()」を使用します。
実際のコードを見て確認してみましょう。
import pandas as pd
#dataframe作成
df = pd.DataFrame([[1,2,3,4,5],[10,20,30,40,50]])
df2 = pd.DataFrame([["あ","い","う"],["月","火","水"]])
#書き出し
with pd.ExcelWriter("out2.xlsx") as writer:
df.to_excel(writer, sheet_name="test1", index=False, header=False)
df2.to_excel(writer, sheet_name="test2", index=False, header=False)
上のように、pd.ExcelWriter()をwithで開いて使います。
結果は下のように、「test1」と「test2」というシートにそれぞれのデータが保存されています。

これで、データが複数あった場合でもデータをexcelに保存することができました。
3.3 既存のexcelに追記しよう(pd.ExcelWriterを使用する場合)
最後に、すでに存在するexcelに追記する方法について解説します。
追記する方法は大きく分けて2つあり、「①pd.ExcelWriter()」をする方法と、「②openpyxl」を使用する方法があります。
まずは「①pd.ExcelWriter()」を使用した追記について解説します。
先ほど作成した「out2.xlsx」に新しく追記してみましょう。
下のコードを実行してみてください。
import pandas as pd
#dataframe作成
df3 = pd.DataFrame([["test1","test2"],[10, 20]])
#書き出し
with pd.ExcelWriter("out2.xlsx", mode="a", engine="openpyxl") as writer:
df3.to_excel(writer, sheet_name="test3", index=False, header=False)すると、下のように「test3」というシートに書き込むことができました。

「複数シートへの書き込み」で使用した「pandas.ExcelWriter()」を用いて、「mode=”a”」として開くことで、上書きではなく追記としてエクセルを開くことが出来ます!
また、「engine=”openpyxl”」として「openpyxl」を使用すると明言しておくとエラーを防ぐことが出来ます。
※自動で判定してくれますが、たまにエラーが出ることもあるので書いておくと無難です。
また、すでに存在するシートに追記することも出来ます。
import pandas as pd
df4 = pd.DataFrame([["test3","test4"],[100, 90]])
with pd.ExcelWriter("out2.xlsx", mode="a", engine="openpyxl", if_sheet_exists="overlay") as writer:
df4.to_excel(writer, sheet_name="test3", index=False, header=False, startrow=2)「pandas.ExcelWriter()」を開くときに「if_sheet_exists=”overlay”」とすることで、シートが存在する場合に追記するモードで開くことが出来ます。
(※ただし、pandasのバージョンが1.4.0以上でないと使えません。)
また、「df.to_excel」で書き出す際に、「startrow=」と「startcol=」でそれぞれ書き出し始める行列の場所を選ぶことが出来ます。
今回は2行目(0始まり)を選んだので、下のように追記することが出来ました。
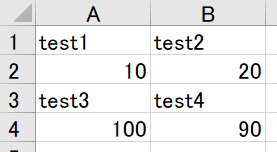
これで、データフレームを好きなエクセルに追記することが出来ますね。
3.4 既存のexcelに追記しよう(openpyxlを使用する場合)
次に、「openpyxl」を使用した追記方法について解説します。
pandasのバージョンが1.4.0以下の時はこの方法しかなかったのですが、前述の方法と好きな方を使えばよいと思います。
ただし、「openpyxl」はデータフレームを直接書き込むことは出来ないので、二次元配列を書き込む関数を定義して使用する必要があります。
(「openpyxl」は個別のセルに書き込んだり、書式を変更したりできるので、そういった用途に向いています)
ですので、pandasの出力だけなら、こだわりが無ければ前述の「pd.ExcelWriter」を使う方が簡単でお勧めです!
では、先ほどから操作している「out2.xlsx」に新しく追記してみましょう。
import openpyxl
# 二次元配列の書き込み関数***************************************
def write_df(sheet, df, start_row, start_col):
for y in range(len(df)):
for x in range(len(df.columns)):
sheet.cell(row=start_row + y,
column=start_col + x,
value=df.iloc[y, x])
#dataframe作成
df5 = pd.DataFrame([["open1","open2"],["追記だよ", "これも追記"]])
# エクセルを開く(ワークブック)
wb = openpyxl.load_workbook("out2.xlsx")
# シートを開く
sheet = wb["test3"]
# 書き出し
write_df(sheet, df5, 3, 3)
# 保存
wb.save("out2.xlsx")これで、下のように追記することが出来ました。
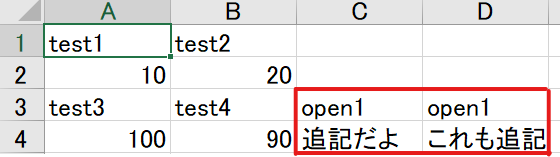
「pd.ExcelWriter」を使った時よりも複雑なコードになっていますね。
同じことが出来るのであれば、コードはシンプルな方が良いと思いますが、知識として知っておくのは良いと思います。
また、古いバージョンのpandasしか使用できない場合もこちらの方法を利用してください。
ある程度何をやっているかを理解したら、形を覚えて使えるようになりましょう!
- excelへの書き込みには、「df.to_excel()」を使用
- 基本的な使い方は「df.to_excel(“出力ファイル名”, sheet_name=”シート名”, index=True, header=True)」
- データが複数ある場合は、「pandas.ExcelWriter()」を使用
- 既存のexcelに追記する場合、「pandas.ExcelWriter(mode=”a”)」とするか、「openpyxl」をインポートして使用
4. おわりに
今回は、pandasを用いてexcelのデータを読み書きする方法について解説しました。csvの読み書き同様、使う機会は多いと思いますので、どちらもマスターしておくといろいろと便利です。
特に、「pandas」は他にもできることがたくさんあるので、ぜひいろいろ使えるように頑張りましょう!
ちなみに、このサイトでは初心者の方向けに「Python初心者入門講座」という講座を作っていますので、気になった方はそちらもご覧いただけると幸いです。









コメント
コメント一覧 (2件)
3.3 既存のexcelに追記しようを参考にさせていただきましたが、
‘Workbook’ object has no attribute ‘add_worksheet’
というエラーが出て解決方法がわからずじまいです。
もし、こういうエラーが出たらどうすればいいか、参考になるブログを書いていただけると助かります。
田中様
ご質問ありがとうござます。
追記の部分の内容が少し古かったため、更新いたしました。
「3.3 既存のexcelに追記しよう(pd.ExcelWriterを使用する場合)」
がシンプルで分かりやすいと思いますので、そちらを参考にされてみてください。
また、田中様のエラー文を見ると、Workbookでadd_worksheetを使用しようとされたように見えるので、
「openpyxl」のWorkbookを使用する際は、「load_worksheet」で読みこんで追記してみてください。
そちらの方法も、「3.4 既存のexcelに追記しよう(openpyxlを使用する場合)」で解説しています。
もしまた分からないことがあればコメント下さればと思います。