
今回は、Pyhonでデータを扱う際に使えるととても便利な「Pandas」について解説したいと思います。
また、データを扱う際に使用する代表的なライブラリとして「numpy」がありますが、2つのライブラリの違いと使い分けについても解説します。
「numpy」の使い方については、「numpyの使い方とlistとの違いを比較」で解説していますので、そちらをご覧ください。
1. Pandasって何?(numpyと比較)
「Pandas」とは、Pythonでデータを扱うためのライブラリで、データを表形式で扱うことができます。
データを扱うライブラリというと、代表的なものに「numpy」がありますが、「numpy」との違いは下記のようなものです。
pandasとnumpyの違い
- numpyは全ての要素が同じ型でなければならないがpandasでは様々な型を使用可能
- pandasではデータに欠損があった場合でも読み込み可能
上記の違いだけを見ると、「pandas」の方が優れているように思えますが、「numpy」は計算に特化しており、計算速度は圧倒的に「numpy」の方が速いです。
そのため、下記のように使い分けることをお勧めします。
pandasとnumpyの使い分け
- 要素ごとに形式が違ったり欠測のあるデータの整理にはpandasを使用
- 数値のみの配列を扱う、または計算を行う場合はnumpyを使用
では、次の章からは実際にコードを動かしながら「pandas」の基本的な使い方について解説していきます。
2. Pandasの基本的な使い方(dataframeの作成)
「pandas」ではデータを表形式で扱うと説明しましたが、「pandas」で作成するこの表形式のデータのことをdataframe(データフレーム)と呼びます。
この「dataframe」は、「pandas.DataFrame(配列)」という形式で作成できます。
※このとき、DataFrameの「D」と「F」は大文字でなければエラーになりますので、注意してください。
では、実際にdataframeを作成してみましょう。
import pandas as pd #list配列の作成 data = [[80,75,90,70,95],[95,80,75,90,65]] #dataframe作成 df = pd.DataFrame(data)
上のコードを実行すると、「df」というdataframeが作成されます。作成されたdataframeは下記のような形ですね。
| 80 | 75 | 90 | 70 | 95 |
| 95 | 80 | 75 | 90 | 65 |
※ちなみに、今回は読み込ませる配列をlistにしましたが、numpyなどの配列でも読み込み可能です。
さて、ここまでは普通の配列と変わりませんが、「pandas」ではこの行や列に名前を付けることができます。
では、実際に名前を付けてみましょう。先ほどのコードに続けて、下のコードを実行してください。
#列名の指定 df.columns = ["国語", "算数", "理科", "社会", "英語"] #行名の指定(index) df.index = ["太郎", "花子"]
すると、行と列にそれぞれ名前が付き、表形式のようになりましたね。
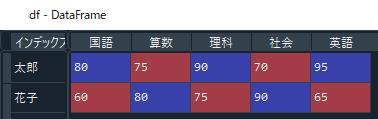
(上の配列はspyderの変数エクスプローラーで確認しています。詳しくは「Spyderの基本と便利な使い方」をご覧ください。)
ちなみに行列名は、下のようにdataframe作成時に「columns=」と「index=」で指定することもできます。
import pandas as pd #list配列の作成 data = [[80,75,90,70,95],[95,80,75,90,65]] #行列名の作成 col = ["国語", "算数", "理科", "社会", "英語"] ind = ["太郎", "花子"] #dataframe作成 df = pd.DataFrame(data, columns=col, index=ind)
また、indexはについては、「df.set_index()」を用いることで、データ作成後に列名を指定してindexにすることもできます。
import pandas as pd #list配列の作成 data = [["太郎",80,75,90,70,95],["花子",95,80,75,90,65]] #dataframe作成 df = pd.DataFrame(data) #indexの列を指定 df = df.set_index(0)
ここまでくれば、あとはこの行や列ごとに平均を出したり、並べ替えたりといろいろな処理を行うことができます。
次の章では、まずこのdataframeからのデータ抽出方法について解説します。
- pandasのdataframeは「pd.DataFrame(配列)」という形式で作成
- 「df.columns =[リスト]」で列名を指定
- 「df.index =[リスト]」で行名(index)を指定
- 行名(index)は「df.set_index()」を用いて後からindexにする列を指定可能
3. Pandas(dataframe)からのデータ抽出
ここでは、作成したdataframeからのデータの取り出し方法について解説します。
dataframeからデータを取りだす方法は、大きく分けて次の2つです。
また、上記2つの方法に共通し、「範囲を指定して抽出する方法」もあります。
では、この3つについてそれぞれ解説していきます。
3.1. 行列名を指定して抽出
まずは、行列名を指定したデータ抽出方法について解説します。
行列名を指定する場合、それぞれ下記のように指定します。
| 行名を指定 | df.loc[“行名”] |
| 列名を指定 | df[“列名”] |
| 行列両方を指定 | df.loc[“行名”, “列名”] |
では、実際にコードを動かして確認してみましょう。
import pandas as pd #list配列の作成 data = [[80,75,90,70,95],[95,80,75,90,65]] #行列名の作成 col = ["国語", "算数", "理科", "社会", "英語"] ind = ["太郎", "花子"] #dataframe作成 df = pd.DataFrame(data, columns=col, index=ind) #国語の点数を抜き出し Japanese = df["国語"] #太郎の点数を抜き出し Taro = df.loc["太郎"] #花子の算数の点数を抜き出し Hanako = df.loc["花子", "算数"]
上のコードを実行すると、Japaneseには二人の国語の点数が、Taroには太郎の点数が、Hanakoには花子の算数の点数がそれぞれ入っていますね。
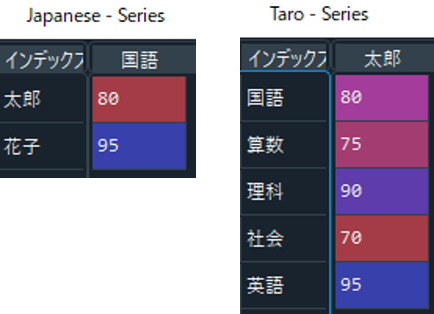
ちなみに、Dataframeから行や列を指定して抜き出した1次元の配列を「Series」と言います。
3.2. 行列の番号を指定して抽出
次に、行番号や列番号を指定してデータを抽出する方法について解説します。
行列の番号を指定する場合、基本的には「df.iloc[行番号, 列番号]」という風に指定します。
ただし、行数や列数のみ指定したい場合は、指定しない方を「:」にすることで指定することができます。(「:」は、すべての範囲という意味になるため)
まとめると、下のように使い分けます。
| 行数を指定 | df.iloc[“行数”, :] |
| 列数を指定 | df.iloc[:, “列数”] |
| 行列数を指定 | df.iloc[“行数”, “列数”] |
では、実際にコードで確認してみましょう。
import pandas as pd #list配列の作成 data = [[80,75,90,70,95],[95,80,75,90,65]] #行列名の作成 col = ["国語", "算数", "理科", "社会", "英語"] ind = ["太郎", "花子"] #dataframe作成 df = pd.DataFrame(data, columns=col, index=ind) #国語の点数を抜き出し(列数指定) Japanese = df.iloc[:, 0] #太郎の点数を抜き出し(行数指定) Taro = df.iloc[0, :] #花子の算数の点数を抜き出し(行列数指定) Hanako = df.iloc[1, 1]
これで、行列名を指定した場合と同じようにデータを抽出できましたね。
行列数の指定は、行列名がしっかり決まっていない時に使用することになります。
3.3. 範囲指定を指定したデータ抽出
最後に、範囲を指定する場合について解説し、データの抽出方法をまとめたいと思います。
範囲を指定する場合は、前項の方法で行列を指定する際に、「始まり:終わり」のようにして指定することができます。
では、具体例を確認してみましょう。(前項のdataframeを使用しています)
#花子の算数から社会の点数を抜き出し Hanako2 = df.loc["花子", "算数":"社会"] Hanako3 = df.iloc[1, 1:4]
上のように「始まり:終わり」とすることで、その範囲のデータを抜き出すことができます。(行列名でも行列数でも同様に処理できます。)
3.4. データ抽出のまとめ
ここまで解説したデータ抽出方法をまとめると以下のようになります。
| 行名を指定 | df.loc[“行名”] |
| 列名を指定 | df[“列名”] |
| 行列名を指定 | df.loc[“行名”, “列名”] |
| 行数を指定 | df.iloc[“行数”, :] |
| 列数を指定 | df.iloc[:, “列数”] |
| 行列数を指定 | df.iloc[“行数”, “列数”] |
範囲を指定 | df.loc[“始行名”:”終行名”, “始列名”:”終列名”] or df.iloc[“始行数”:”終行数”, “始列数”:”終列数”] |
- 行列を名前で指定する場合は「df.loc[“行名”, “列名”]」
- 行列を数字で指定する場合は「df.icol[“行数”, “列数”]」
- 範囲を指定する場合は行列を「始まり:終わり」で指定
4. Pandasによるcsvの読み込み(read_csv)
最後に、pandasによるcsvの読み込みについて解説します。
pandasでcsvを読み込む場合には、「read_csv」を使用します。
では、実際にコードを動かしながら確認してみましょう。
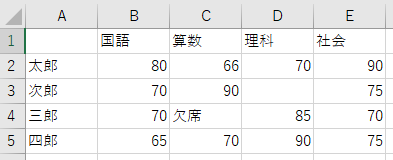
今回は下のようなcsvファイル読み込んでみます。(ファイル名はcsv_data.csvです)
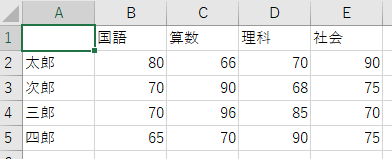
import pandas as pd
df = pd.read_csv("csv_data.csv", header=0, index_col=0, encoding="SHIFT-JIS")
これで下のようにcsvデータを読み込むことができました。コードとしてはかなり簡単ですね。
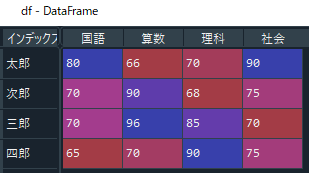
上のコードでread_csvを使用した際のポイントは下の点です。
- 「header=」でヘッダー(列名)の行を指定できる
- 「index_col=」でindexの列を指定できる
- 日本語を読み込む場合は「encoding=”SHIFT-JIS”」を使う
ちなみに、ヘッダーが無いデータを読み込む場合は下の2種類の方法があります。
- header=Noneとすることで、ヘッダー無しのデータを読み込む
- names=[リスト]とすることで、列名を指定して読み込む
また、index_colは指定しなければ読み込まないため、indexが無い場合は指定しなくて構いません。
このように、pandasではcsvのデータを簡単に表形式に読み込むことができます。
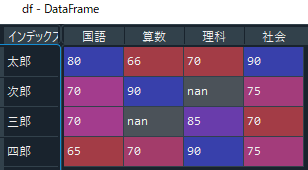
ちなみに、データに欠損(空白など)がある場合は「nan」に変換されます。また、「na_values」を用いることで、欠損値の指定をすることもできます。
上と同じ方法で読み込むと、空白のみが欠損となり「nan」に変換される。

下のように、「na_values」で「欠席」も欠損値に指定することができる。
import pandas as pd
df = pd.read_csv("csv_data.csv", header=0, index_col=0,na_values="欠席", encoding="SHIFT-JIS")
- pandasでcsvを読み込む場合は「read_csv」を使用
- 「header=」でヘッダー(列名)の行を指定
- 「index_col=」でindexの列を指定
- 「header=None」とすることでヘッダー無しのデータの読み込み
- 「names=[リスト]」とすることで列名を指定して読み込み
- 「na_values=」で欠損値を指定
5. おわりに
今回は、pythonでデータを扱う際に使えると便利な「pandas」について解説しました。
最初は少し難しく感じるかもしれませんが、「pandas」は使えるようになるとかなり便利なので、ぜひ使い方をマスターしてください。
ちなみに、このサイトでは初心者の方向けに「Python初心者入門講座」という講座を作っていますので、気になった方はそちらもご覧いただけると幸いです。









コメント