
今回は、Pyhonでデータを扱う際に使えるととても便利な「Pandas」について、同じくデータを扱う際に使用する代表的なライブラリである「numpy」と比較して解説したいと思います。
「Pandas」の基本については、「Pandasの基本的な使い方について」で解説していますので、そちらをご覧ください。
1. Pandasとnumpyの違いについて
まずPandasとは、Pythonでデータを扱うためのライブラリで、データを表形式で扱うことができます。
データを扱うライブラリというと、代表的なものにnumpyがありますが、numpyとの違いは下記のようなものです。
pandasとnumpyの違い
- numpyは全ての要素が同じ型でなければならないがpandasでは様々な型を使用可能
- pandasではデータに欠損があった場合でもNanとして読み込み可能
では、上記点についてそれぞれ解説していきます。
1.1. numpyとpandasのデータ形式について
下の配列をnumpyとpandasに読み込ませた場合、以下のようになります。
| 1 | 2 | 3 | 4 | 5 |
| あ | い | う | え | お |
numpyではすべての要素が同じ型でなければならないため、1行目の数字も文字として読み込まれます。
pandasでは様々な型が混在可能なので、1行目は整数、2行目は文字として読み込むことができます。
実際にコードを動かして確認してみましょう。
import numpy as np import pandas as pd #配列の作成 data = [[1,2,3,4,5],["あ","い","う","え","お"]] #numpy形式での読み込み ndata = np.array(data) print(ndata[0,2], type(ndata[0,2])) #pandas形式での読み込み pdata = pd.DataFrame(data) print(pdata.iloc[0,2], type(pdata.iloc[0,2]))
上のコードを実行すると、同じ「3」を出力した場合でも、numpyは文字(str)で出力され、pandasでは整数(int)で出力されていますね。
このように、pandasでは要素ごとに違う形式のデータを扱うことができます。
1.2. 欠損があるデータの読み込みについて
次に、データに欠損がある場合についてです。
下のような欠損(空白)のある「input.csv」というcsvデータを用意し、「numpy」と「pandas」でそれぞれ読み込んでみましょう。
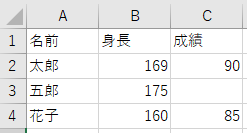
では、まず「numpy」を用いたデータの読み込みです。
import numpy as np
data = np.loadtxt("input.csv", delimiter=",", dtype = "unicode")
print(data)
上のコードを実行すると、空白だった部分はそのまま空白として読み込まれます。
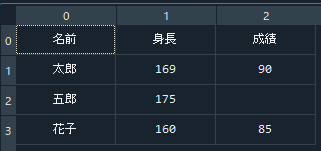
※空白や文字を含む場合は、「dtype=”unicode”」と記述し、文字として読み込まないとエラーになります。
上記のように、numpyでも一応データを読み込むことができるのですが、欠損があると全体を文字として読み込む必要があり、後のデータ処理で邪魔になります。
では、次に「pandas」を用いて読み込んでみましょう。
import pandas as pd
df = pd.read_csv("input.csv", header=0, index_col=0, encoding="SHIFT-JIS")
print(df)
上のコードを実行すると、欠損を「Nan」として読み込むことができます。
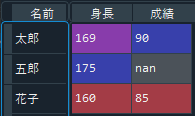
「Nan」としてデータを読んでおくと、後にデータの平均を取ったり合計を取ったりする際も、除外できたりと何かと便利です。
また、後で解説しますが、「Nan」としてデータを読み「numpy」へ変換することで、numpy配列でも欠損を扱うことができるようになります。
そして何より、他の値を数値として読み込むことができる点が「numpy」よりも優秀な点です。
このように、文字と数字が混じったデータであったり、欠損のあるデータを読み込む際は、「Pandas」を使うことで後のデータ処理を楽に行うことができます!
- numpyではすべての要素が同じ型の必要あり
- pandasでは様々な型が混在可能
- 空白や文字を含むデータを読み込む際は「Pandas」を使用する
2. Pandasとnumpyの変換
先ほど、文字や空白のあるデータを読み込む際は「Pandas」の使用をおすすめしましたが、データは「numpy」で扱いたい等あると思います。
そこで次に、Pandasとnumpyを相互に変換する方法について解説します。
※「numpy」は計算に特化したライブラリであり、計算は「Pandas」より速いです。
2.1. Pansasをnumpyに変換する方法
まずは、「Pandas」から「numpy」への変換についてです。
「Pandas」から「numpy」への変換には、「to_numpy」というメソッドを使用します。では、実際に先ほどの「input.csv」を読み込んで変換してみましょう。
import pandas as pd
df = pd.read_csv("input.csv", header=0, index_col=0, encoding="SHIFT-JIS")
data = df.to_numpy()
すると、下のような「data」というnumpy配列が出来たと思います。
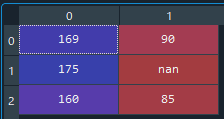
ここで重要なのが、「nan」は文字ではなく実数(float64)として読み込まれていることです。
下のコードを実行し、「nan」が実数として読み込まれていることを確認しましょう。
print(data[1,1], type(data[1,1]))

つまり、欠損のあるデータは一度「Pandas」で読み込み、その後「numpy」へ変換することで、numpy配列として扱うことができるのです。
また、「Pandas」で読み込んだ際の、インデックスやヘッダーは除外されて変換されますので、そういったデータを扱う際も、この方法が良いと思います。
2.2. numpyをPandasに変換する方法
次に、numpyをPandasに変換する方法についてです。
この場合は、pandasの「DataFrame」を使用します。
「DataFrame」の作成方法や使い方については「Pandasの基本的な使い方について」で解説していますので、そちらもご覧ください。
では、実際にコードを動かして確認してみましょう。
import pandas as pd import numpy as np data = np.arange(12).reshape(3,4) df = pd.DataFrame(data)
上のように、「pandas.DataFrame(配列)」とすることでnumpy配列からpandasの配列へ変換することができます。
使用頻度としては、「Pandas」から「numpy」への変換の方が高いと思いますので、しっかりと使えるようになりましょう。
- 「Pandas」から「numpy」への変換には「to_numpy」というメソッドを使用
- 「to_numpy」では「nan」は文字ではなく実数(float64)として読み込み
- 欠損のあるデータは一度「Pandas」で読み込みその後「numpy」へ変換する
- 「numpy」を「Pandas」に変換するにはpandasの「DataFrame」を使用
3. まとめ
今回は、「Pandas」と「numpy」における違いや相互変換について解説しました。
「Pandas」や「numpy」を状況に応じてうまく使い分けることでデータ処理がとても楽になりますので、ぜひマスターしてもらいたいと思います。
このサイトでは初心者の方向けに「Python初心者入門講座」という講座を作っていますので、気になった方はそちらもご覧いただけると幸いです。









コメント