
Pythonは、ほかの言語に比べネットからデータを取ってくる事が得意な言語です。この、ネットからデータを取ってくることを「webスクレイピング」と呼びます。
普段私たちが見ているサイトの情報などは、基本的にこの「webスクレイピング」を使用することによって自動で取得することができます。
今回はこの「webスクレイピング」について解説していきます。
1.webスクレイピングって何?
ネットからデータを取ってくることを「webスクレイピング」と呼ぶと解説しましたが、厳密には「サイトのHTMLからデータを抜いてくること」を指します。
webサイトの基本情報はHTMLというプログラムで構成されており、このHTMLを解析することで、サイトから欲しいデータを取得することができます。
ちなみにHTMLとは下のようなものです。これだけ見ると、難しい気がしますね…

ただし、ここからデータを取ってくることは、基本を押さえればそれほど難しいことではありません!
HTMLの詳しい話は置いておいて、次の章では実際にどのようにデータを取得するのか解説していきます!
2.webスクレイピングを行ってみよう
では、実際にwebスクレイピングを実施してみます。
今回は、yahooのトップニュースのタイトルをスクレイピングしてみましょう。
まずは、下のコードを実行し、どのようにデータを取得できるのか確認してみましょう!(詳しい解説は後ほど行います。)
from bs4 import BeautifulSoup
import requests
#yahooのニュースサイトのurl
url = "https://news.yahoo.co.jp/"
#requestsによりHTMLを取得
r = requests.get(url)
#日本語文字化けを防止
r.encoding = r.apparent_encoding
#BeautifulSoupによりデータを取り出しやすい形に変換
soup = BeautifulSoup(r.content, "html.parser")
#トピックニュースの塊を指定
topic = soup.find("ul", class_="topicsList_main")
#トピックニュースの塊からそれぞれのニュースを抽出
rows = topic.findAll("a")
news = []
for row in rows:
news.append(row.get_text())
print(news)
上のコードを実行すると、「news」というlistに、トップニュースのタイトルが入っていることを確認できると思います。
下は、私がコードを実行したときのサイトの状況と取得したタイトルです。ちゃんと一致していますね。
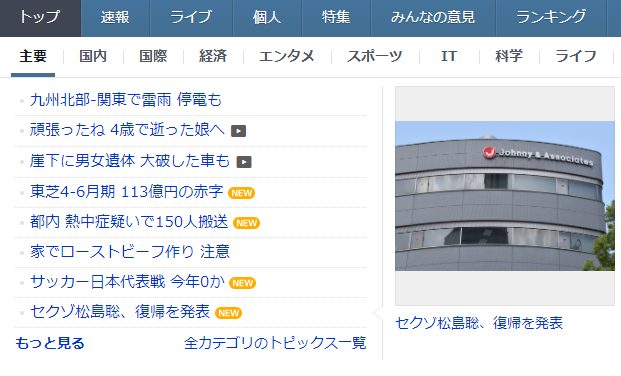
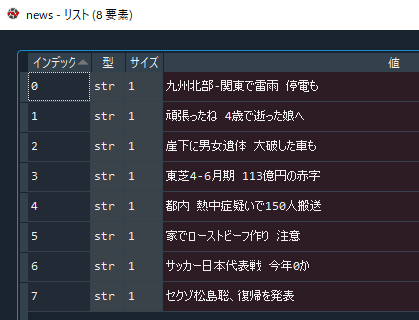
このように、わざわざwebサイトに行かなくてもデータを取得することができます!
では、実際にコードを細かく解説していきます。
手順1 必要なライブラリをインポート
まず、webスクレイピングでは基本的に、HTMLを読み込んでくる「requests」と、読んできたHTMLからデータを抜き出しやすくする「BeautifulSoup」を使用します。
ですので、この2つのライブラリをインストールし、初めにインポートします。
from bs4 import BeautifulSoup import requests
ライブラリのインストールに不安がある方は、このサイトの「Pythonのライブラリを使ってみよう」で解説していますのでそちらをご覧ください。
手順2 サイトのHTMLを取得しよう(requests)
次に、データを抜き出したいサイトのHTMLを取得します。HTMLの取得には「requests」を使います。
「requests.get(サイトのurl)」でサイトにアクセスし、「content」を使うことでHTML(バイナリ)を取得することができます。
#yahooのニュースサイトのurl url = "https://news.yahoo.co.jp/" #requestsによりHTMLを取得 r = requests.get(url) html = r.content #日本語文字化けを防止 r.encoding = r.apparent_encoding
※「content」の代わりに「text」を使うとHTML(テキスト)を取得でき、基本的に同じ操作ができます。ただし、画像などをダウンロードしたい場合は「content」を使う必要があるため、「content」をお勧めします。
また、サイトを読み込む際に日本語が文字化けしてしまうことがあるため、それを防ぐために「r.encoding = r.apparent_encoding」と記述しています。(必須ではないです。)
手順3 データを取り出しやすい形に変換しよう(BeautifulSoup)
次に、「BeautifulSoup」を使って、取得したHTMLからデータを抜き出しやすい形に変換します。
使い方は、「BeautifulSoup(サイトのhtml, “html.parser”)」という風に使います。
#BeautifulSoupによりデータを取り出しやすい形に変換 soup = BeautifulSoup(html, "html.parser")
※「html.parser」の部分はパーサーと呼ばれているもので、htmlを解析する方法を示しています。ほかにもhtml5libやlxmlなどがありますが、これらは別でインポートする必要があるため、基本はPythonに標準搭載されている「html.parser」を使えば問題ありません。
手順4 欲しいデータを取得しよう
最後に、htmlの中で実際に欲しいデータを取得していきます。
手順4.1. 対象個所のhtmlを確認
まず欲しいデータを取得するために、htmlのどこにその情報が記載されているかを調べる必要があります。
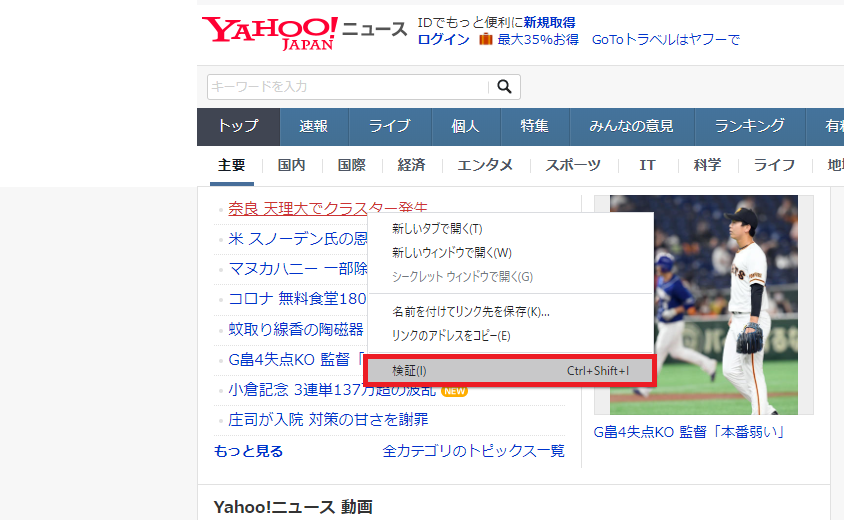
「Google Chrome」の場合は、取得したい個所を右クリックし、「検証」をクリックすることで、欲しい情報がhtmlのどこに記載されているか調べることができます。
使っているブラウザによって名前は違いますが、同じ機能があります。(ちなみに、Microsoft Edgeの場合は「開発者ツールで調査する」、Firefoxの場合は「要素を調査」になります。)
下のように、欲しい情報を右クリックし、検証をクリックします。
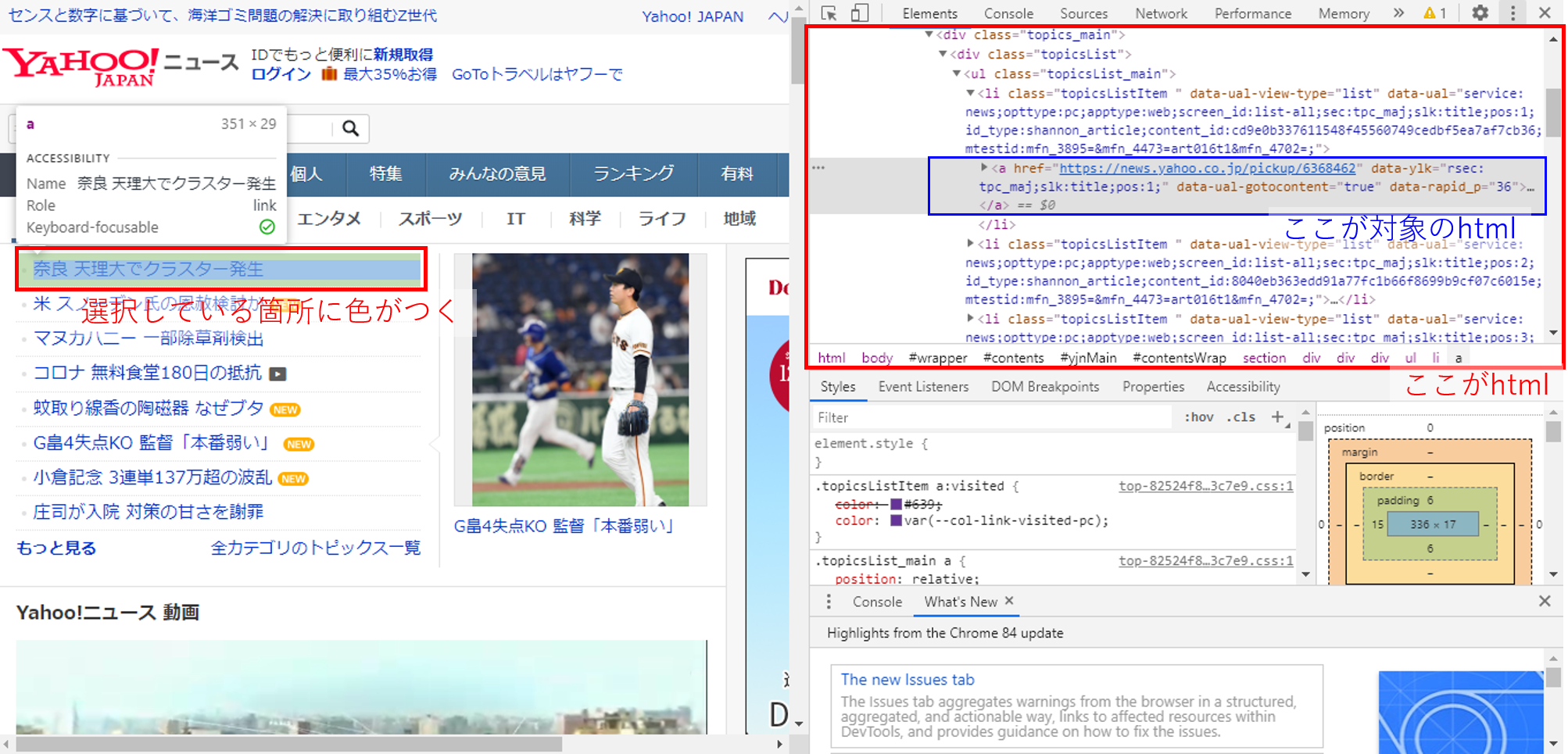
すると、下のように対象個所のhtmlが表示されます。
手順4.2. トップニュースの塊のhtmlを選択
次に、先ほど調べたhtmlの場所を指定します。
今回欲しいトップニュースは、先ほどの方法で表示させたhtmlで確認すると、「<ul class=”topicsList_main”>」という塊にまとまっていることが分かります。
※個々のニュースより少し上のhtmlにマウスカーソルを合わせると、下の画像のようにトップニュースが全部選択されます。
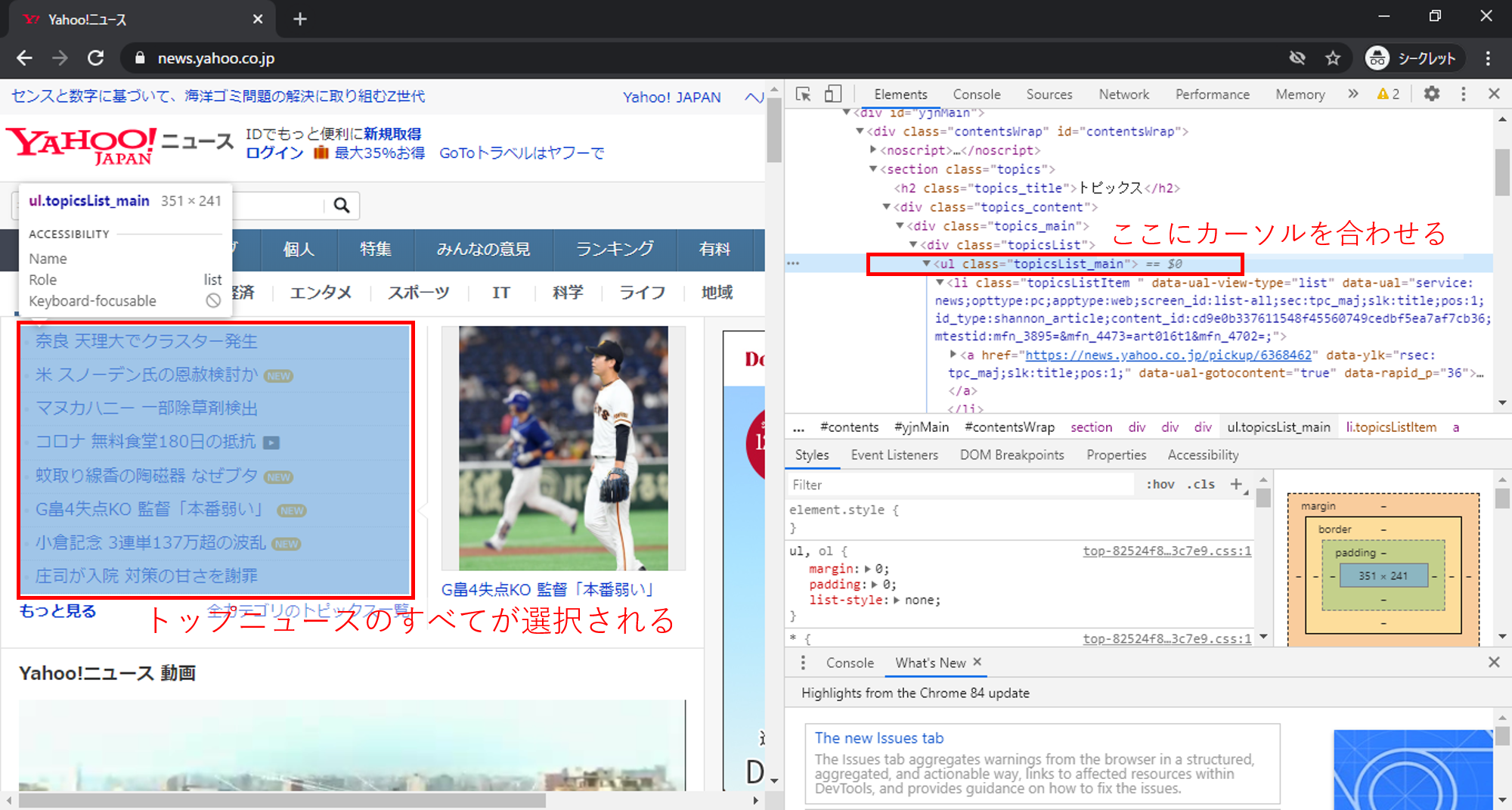
この塊をスクレイピングために、今回は「soup.find」を使います。「find」は、タグ名で検索することができます。(他にもいろいろな方法があります。)
使い方は、「soup.find(タグ名、情報)」という風に使います。
今回は、タグが「ul」、クラス名が「topicsList_main」と分かっているため、そのように記述しています。
※classの時のみ、「class_」のようにアンダーバーを付けます。
#トピックニュースの塊を指定
topic = soup.findAll("ul", class_="topicsList_main")
手順4.3. 個々のニュースを抽出
そして、次はいよいよトップニュースの塊の中から個々のニュースを取り出していきます。
抽出する要素が複数の場合は、「findAll」を使うことで条件に合うすべての要素を「list」として取得することができます。(使い方は基本的に「find」と同じです。)
個々のニュースは、タグ名「a」でくくられているため、「findAll(“a”)」として抽出します。
#トピックニュースの塊からそれぞれのニュースを抽出
rows = topic[0].findAll("a")
最後に、抽出した要素からタグの中の文字のみ抜き出すために「get_text()」を使用します。
※「get_text()」は「list」に対して使えないため、「list」でループを回し、一つずつ処理します。
news = []
for row in rows:
news.append(row.get_text())
print(news)
リストのループに関しては下の記事で紹介していますので、気になった方はそちらもご覧ください。

これで、ヤフーニュースからトップニュースを取得することができました!
3. まとめ
今回は、「webスクレイピング」について解説しました。今回の内容を応用すると、定期的にチェックしたいネットの情報を保存しておき、後で確認するなんてこともできるようになります。
ぜひマスターしてより便利にPythonを使えるようになりましょう!
このサイトでは初心者の方向けに「Python初心者入門講座」という講座を作っていますので、気になった方はそちらもご覧いただけると幸いです。









コメント