
Pythonでデータを扱う際に、データをcsvから読み込むことは多いと思います。
ただし、その方法はいくつかあり、最初はどれを使えばいいか迷うと思います。
そこで、今回はcsvファイルの読み込みについて、標準ライブラリ、numpy、Pandasの3つの方法に分けて解説し、おすすめの使い分けについても説明したいと思います。
※基本的には「numpy」か「Pandas」を使う方法がおすすめです。
1. 標準ライブラリを用いたcsvの読み込み
まずは、標準ライブラリである「csv」を用いたデータの読み込みについて解説します。
※ただし、この方法はコードが比較的長く、またループ処理でデータを抜き出す必要もあるため、「csvファイル」を読み込む方法としてはあまりお勧めできません。
では、今回は下のようなcsvファイルを読み込んでみます。(input.csvという名前)
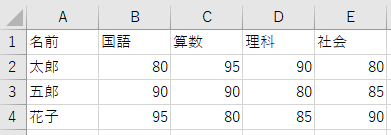
import csv
with open("input.csv", encoding='SHIFT-JIS') as f:
rows = csv.reader(f)
data = []
for row in rows:
data.append(row)
上のコードを実行することで、「data」というlist形で読み込むことができます。
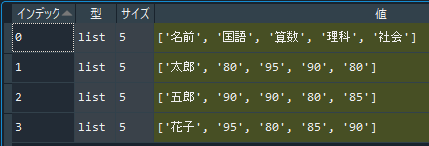
この「csv」を使ったデータの読み込みについては、下の記事で紹介していますので、気になった方はそちらをご覧ください。

どうしてもデータをlist形式で扱いたい!や、外部ライブラリを使いたくない!ということが無ければ、下で紹介する「numpy」か「Pnadas」を使うことをお勧めします。
※numpy配列もlist形式に変換できるので、list形式で扱いたい方も「numpy」を使う方が良いと思います。
- 標準ライブラリ「csv」を用いるとコードが複雑になる
- こだわりがない限り「numpy」か「pandas」を利用する
2. numpyを用いたcsvの読み込み
では次に、「numpy」を用いたcsvファイルの読み込みについて解説します。
「numpy」を用いたデータの読み込みには、「np.loadtxt()」というものを使います。
では実際のコードを見ながら使い方を確認してみましょう。
import numpy as np
data = np.loadtxt("input.csv", delimiter=",", dtype = "unicode")
上のように、たった2行でcsvファイルを読み込むことができます。標準ライブラリを使った時と比べ、かなり簡単に読み込めましたね。
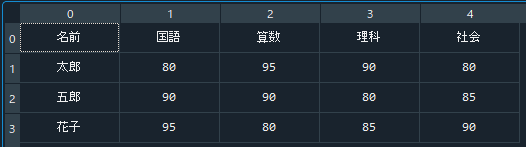
ただし、注意点が2つありますので、そこを解説したいと思います。
csvファイルとは、コンマ区切りのファイルのことです。
一方、「loadtxt」のデフォルトの区切り文字はスペース( )なので、「delimiter=」を使って区切り文字をコンマ(,)に指定する必要があります。
「loadtxt」のデフォルトのデータ型は「実数(float)」なので、文字を読み込むとエラーになってしまうためです。
ちなみに、数字は文字としても読み込めるため、文字を含む場合は「dtype = “unicode”」としておけば問題ありません。
以上の2点を抑えれば、「numpy」を用いてcsvファイルを読み込むことができるようになります。
- 「numpy」を用いたデータの読み込みには「np.loadtxt()」を使用
- csvファイルを読み込むときは「delimiter=”,”」で区切り文字をコンマ(,)に指定
- 日本語を含む場合は「dtype = “unicode”」を用いて文字として読み込む
3. pandasを用いたcsvの読み込み
最後に、「pandas」を用いたcsvファイルの読み込みについて解説します。
「pandas」を用いたデータの読み込みには、「pd.read_csv()」というものを使います。
では実際のコードを見ながら使い方を確認してみましょう。
import pandas as pd
df = pd.read_csv("input.csv", header=0, index_col=0, encoding="SHIFT-JIS")
こちらも、「numpy」同様2行でデータの読み込みが完了します。
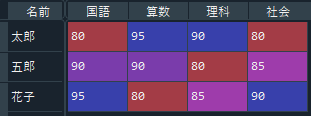
「numpy」との大きな違いは、行や列に「header」や「index」といった名前を付けられる点です。
他の読み込み方では、国語や算数といった列名と、太郎や五郎といった行名も配列のデータとして読み込みますが、「pandas」では、それらを行列名として扱うことができます。
そうすることで、後々データを取り出す際に行列名で指定できたりととても便利です。
そして、その指定をしているのが「header=」と「index_col=」です。
「header=」で、ヘッダー(列名)にする行を選びます。この時、ヘッダーより上の行は読み込まれなくなります。
「index_col=」では、インデックス(行名)にする列を選べます。こちらは、どの列をインデックスにしても他が読み込まれないことはありません。
また、日本語を読み込む際は「encoding=”SHIFT-JIS”」としてください。
ちなみに、「pandas」の詳しい使い方については下の記事で紹介していますのでそちらもご覧いただけると幸いです。

以上のことから、読み込むcsvファイルの配列に、行列名を含む場合は「pandas」を用いることをお勧めします。
- 「pandas」を用いたデータの読み込みには「pd.read_csv()」を使用
- 「pandas」では行や列に「header」や「index」といった名前を付けられる
- 「header=」でヘッダー(列名)にする行を指定
- 「index_col=」でインデックス(行名)にする列を指定
4. まとめ
今回は、csvファイルの読み込みについて、標準ライブラリ、numpy、Pandasの3つの方法に分けて解説しました。
使い分けのポイントをまとめると以下のようになります。
- 基本的には「numpy」か「pandas」を使用
- 行列名を含むデータの場合は「pandas」を使用
- それ以外の時は「numpy」を使用(pandasでも可)
csvファイルを読み込むことは多々あると思いますので、今回の内容が皆様の手助けになればと思います。
また、このサイトでは初心者の方向けに「プログラミングのお勧め学習法」も紹介していますので、気になった方はそちらもご覧いただけると幸いです。









コメント